2024年10月5日 星期六 考勤打卡数据分析 案例
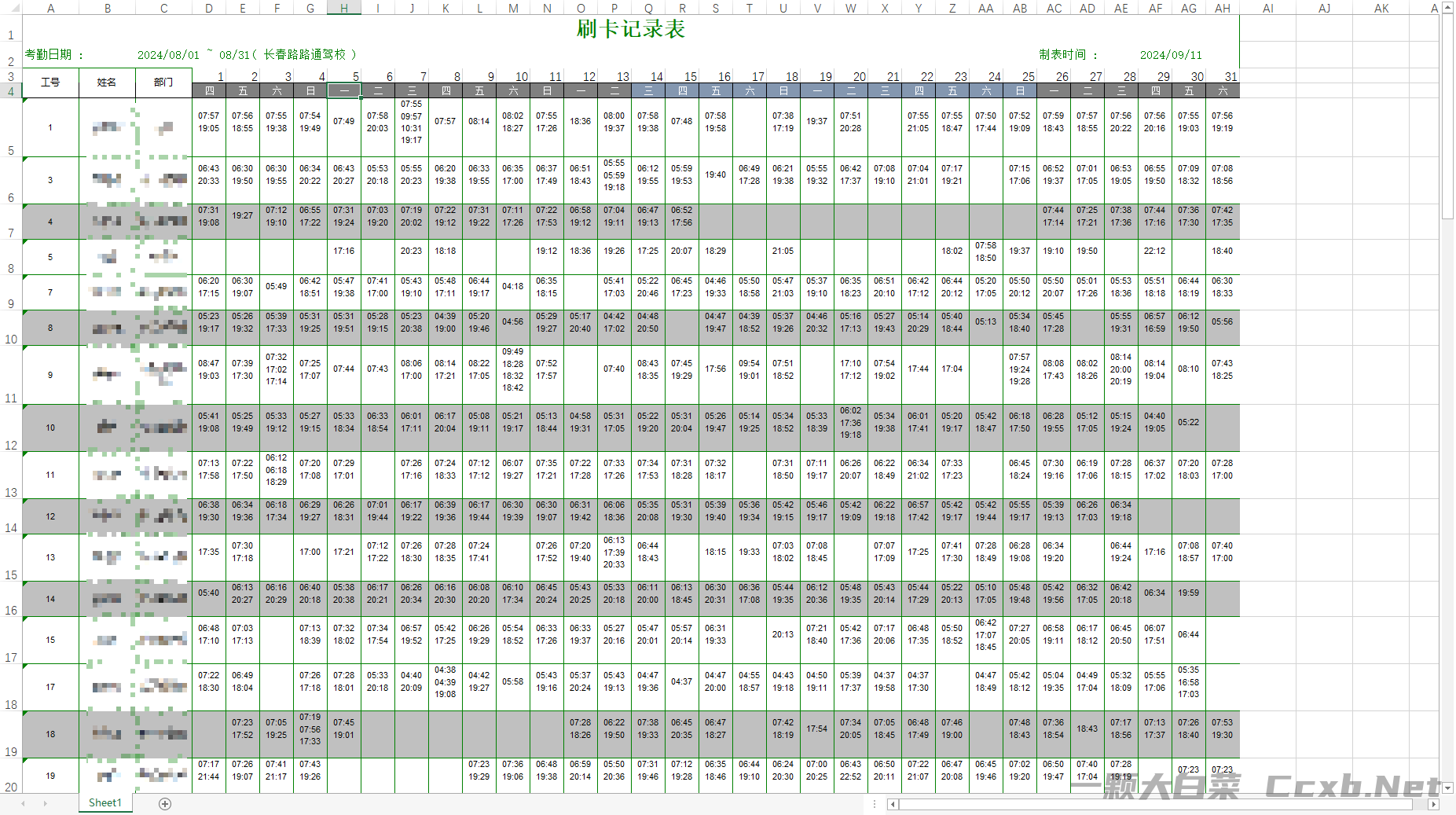
原始表格:
一、软件概述
本软件是一个考勤管理系统,主要用于处理和展示员工的考勤数据。通过导入特定格式的 Excel 文件,可以对员工的考勤情况进行统计和分析,并能够查看特定员工的详细考勤记录。
二、使用要求
导入表格必须为 .xlsx 格式,表格内容应包含员工的工号、姓名、部门以及 1 到 31 天的考勤记录(可包含打卡时间或者空白表示未打卡)。
表格中,前四行数据会被跳过读取。
三、考勤时间判断规则
默认班次:
上班时间为 08:00,下班时间为 17:00。
若员工打卡时间晚于 08:00,则记为迟到。
若员工下班打卡时间早于 17:00,记为缺卡。
学员服务中心_早班:
上班时间为 08:00,下班时间为 17:00。
判断早班情况:
若员工打卡时间晚于 08:00,或者在 08:00 但分钟数大于 0,则记为迟到。
若最后一次打卡时间不在 17:00 之后,则记为缺卡。
学员服务中心_晚班:
上班时间为 10:00,下班时间为 19:00。
若员工打卡时间在 10:00 之前或者 19:00 之后,则认为是晚班。
四、功能介绍
导入文件:
通过点击 “选择文件” 按钮,可以选择要导入的考勤数据 Excel 文件。
导入后,系统会自动读取文件内容,并在树形控件中展示考勤概要。
显示考勤概要:
树形控件展示的考勤概要包括工号、姓名、部门、迟到次数、缺卡次数、正常休息天数、额外休息天数和晚班次数。
可以点击 “部门” 列标题对员工进行排序,但导出统计数据时不会根据排序后的结果导出。
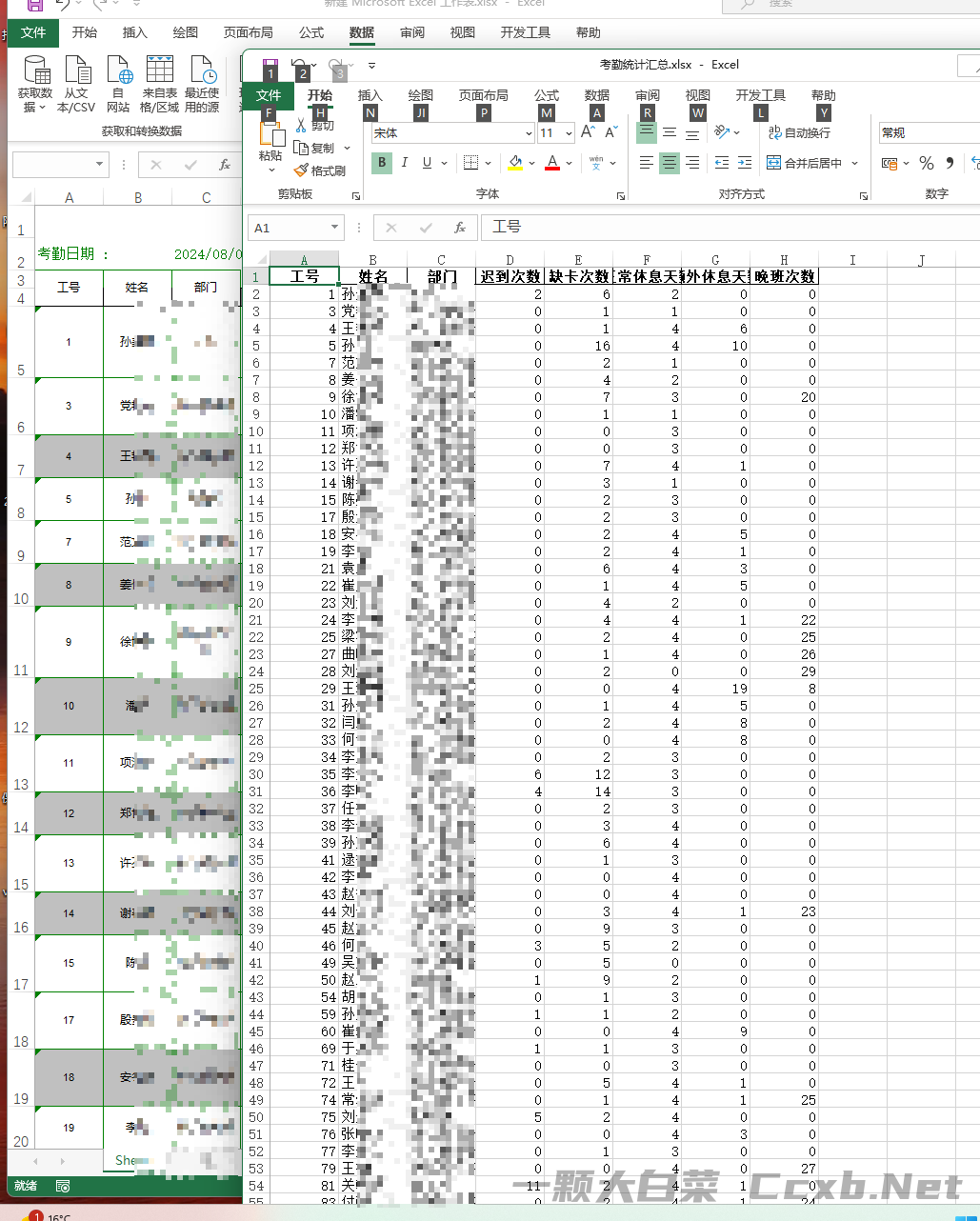
导出统计数据:
点击 “导出统计数据” 按钮,可以将统计后的考勤数据导出为一个新的 Excel 文件,文件名为 “考勤统计汇总.xlsx”。
五、注意事项
软件在运行过程中可能会出现错误,如无法加载文件等情况,请检查文件格式和内容是否正确。
在处理考勤数据时,系统会根据设定的规则进行统计,但可能会存在一些特殊情况无法准确判断,需要人工进行核实。
导出的统计数据仅为当前导入文件的统计结果,不会保留历史数据。若需要多次统计,每次都需要重新导入文件。
软件由“一颗大白菜”设计开发,如遇到问题可联系本人调整。微信、QQ:35515105 电话:18686626826 。
成品文件:

import pandas as pd
import tkinter as tk
from tkinter import ttk
from tkinter import filedialog
# 全局变量
filepath = None
attendance_summary = {}
def load_attendance_data(filepath):
"""加载考勤数据"""
try:
df = pd.read_excel(filepath, header=None, skiprows=4,
names=['工号', '姓名', '部门'] + [str(i) for i in range(1, 32)])
print(f"读取的DataFrame列名: {df.columns.tolist()}")
return df
except Exception as e:
print(f"加载文件时出现错误:{e}")
return None
def process_attendance(df, progress_var):
"""处理考勤数据并更新进度"""
RULES = {
'default': {'check_in': '08:00', 'check_out': '17:00'},
'学员服务中心_早班': {'check_in': '08:00', 'check_out': '17:00'},
'学员服务中心_晚班': {'check_in': '10:00', 'check_out': '19:00'},
'新媒体_早班': {'check_in': '08:00', 'check_out': '17:00'}, # 添加新媒体规则
'新媒体_晚班': {'check_in': '10:00', 'check_out': '19:00'}, # 添加新媒体规则
}
attendance_summary.clear()
total_rows = len(df) if df is not None else 0
for index, row in df.iterrows():
if df is None:
break
try:
employee_id = row['工号']
name = row['姓名']
department = row['部门']
# 修改此处以支持新媒体部门
if '早班' in str(department):
shift = '早班'
rules_key = f'{department}_{shift}' if department in ['学员服务中心', '新媒体'] else 'default'
elif '晚班' in str(department):
shift = '晚班'
rules_key = f'{department}_{shift}' if department in ['学员服务中心', '新媒体'] else 'default'
else:
shift = 'default'
rules_key = 'default'
rules = RULES.get(rules_key, RULES['default'])
except KeyError as e:
print(f"缺少必要的列: {e}")
continue
attendance_summary[employee_id] = {
'name': name,
'department': department,
'late': 0,
'missed': 0,
'rest': 0,
'extra_rest': 0,
'evening_shifts': 0,
# 修改此处以设置新媒体部门的背景颜色
'bg_color': '#b0dfe9' if department == '新媒体' else '#f0f0f0' if department == '学员服务中心' else '#ffffff'
}
days = list(filter(lambda x: isinstance(x, str) and x.isdigit(), row.keys()))
for day in days:
if pd.isnull(row[day]):
if attendance_summary[employee_id]['rest'] < 4:
attendance_summary[employee_id]['rest'] += 1
else:
attendance_summary[employee_id]['extra_rest'] += 1
continue
punches = row[day].split('\n')
if len(punches) == 0:
if attendance_summary[employee_id]['rest'] < 4:
attendance_summary[employee_id]['rest'] += 1
else:
attendance_summary[employee_id]['extra_rest'] += 1
continue
valid_punches = [punch for punch in punches if ':' in punch]
if department == '学员服务中心' and len(valid_punches) == 1:
attendance_summary[employee_id]['missed'] += 1
print(f"{employee_id} missed on day {day}: {valid_punches}")
continue
if len(valid_punches) < 2:
attendance_summary[employee_id]['missed'] += 1
print(f"{employee_id} missed on day {day}: {valid_punches}")
continue
first_punch = pd.to_datetime(valid_punches[0]).time()
last_punch = pd.to_datetime(valid_punches[-1]).time()
if department == '学员服务中心':
if any(t.hour < 10 or t.hour >= 19 for t in (first_punch, last_punch)):
rules = RULES['学员服务中心_晚班']
shift = '晚班'
attendance_summary[employee_id]['evening_shifts'] += 1
else:
# 判断早班情况
if shift == '早班':
if first_punch.hour > 8 or (first_punch.hour == 8 and first_punch.minute > 0):
attendance_summary[employee_id]['late'] += 1
# 判断最后一次打卡是否在 17:00 之后
if last_punch.hour > 17 or (last_punch.hour == 17 and last_punch.minute > 0):
# 这里标记为非有效考勤,但不影响迟到和缺卡统计
pass
else:
attendance_summary[employee_id]['missed'] += 1
print(f"{employee_id} missed on day {day}: {valid_punches}")
# 对非学员服务中心的迟到情况也进行判断
if first_punch.hour >= int(rules['check_in'].split(':')[0]) and department != '学员服务中心':
attendance_summary[employee_id]['late'] += 1
if last_punch.hour < int(rules['check_out'].split(':')[0]) and department != '学员服务中心':
attendance_summary[employee_id]['missed'] += 1
print(f"{employee_id} missed on day {day}: {valid_punches}")
# 更新进度条
progress_var.set(index / total_rows * 100)
root.update_idletasks()
return attendance_summary
def display_attendance_summary(summary, tree):
"""在树形控件中展示考勤概要"""
for item in tree.get_children():
tree.delete(item)
for emp_id, info in summary.items():
tree.insert("", "end", text=emp_id, values=(
emp_id,
info['name'],
info['department'],
info['late'],
info['missed'],
info['rest'],
info['extra_rest'],
info['evening_shifts']
), tags=(info['bg_color'],))
tree.tag_configure('#ffffff', background='#ffffff')
tree.tag_configure('#f0f0f0', background='#f0f0f0')
tree.tag_configure('#c4c4c4', background='#c4c4c4')
def browse_file():
"""选择文件对话框"""
global filepath
selected_filepath = filedialog.askopenfilename(filetypes=[("Excel files", "*.xlsx")])
if selected_filepath:
filepath = selected_filepath
attendance_df = load_attendance_data(filepath)
global attendance_summary
progress_var.set(0)
if attendance_df is not None:
attendance_summary = process_attendance(attendance_df, progress_var)
display_attendance_summary(attendance_summary, tree)
progress_var.set(100)
else:
print("无法加载文件,请检查文件格式或内容。")
def export_marked_data():
"""导出统计后的数据"""
global attendance_summary
if not attendance_summary:
print("请先加载考勤数据")
return
export_data = {
'工号': [],
'姓名': [],
'部门': [],
'迟到次数': [],
'缺卡次数': [],
'正常休息天数': [],
'额外休息天数': [],
'晚班次数': []
}
for emp_id, info in attendance_summary.items():
export_data['工号'].append(emp_id)
export_data['姓名'].append(info['name'])
export_data['部门'].append(info['department'])
export_data['迟到次数'].append(info['late'])
export_data['缺卡次数'].append(info['missed'])
export_data['正常休息天数'].append(info['rest'])
export_data['额外休息天数'].append(info['extra_rest'])
export_data['晚班次数'].append(info['evening_shifts'])
export_df = pd.DataFrame(export_data)
marked_filepath = "考勤统计汇总.xlsx"
export_df.to_excel(marked_filepath, index=False)
print(f"已导出考勤统计数据到: {marked_filepath}")
return marked_filepath
def show_info():
"""显示说明信息"""
info_window = tk.Toplevel(root)
info_window.title("使用说明")
info_window.geometry("1000x400") # 窗口大小
info_text = (
"一、软件概述\n"
"本软件是一个考勤管理系统,主要用于处理和展示员工的考勤数据。通过导入特定格式的 Excel 文件,可以对员工的考勤情况进行统计和分析,并能够查看特定员工的详细考勤记录。\n\n"
"二、使用要求\n"
"导入表格必须为 .xlsx 格式,表格内容应包含员工的工号、姓名、部门以及 1 到 31 天的考勤记录(可包含打卡时间或者空白表示未打卡)。\n"
"表格中,前四行数据会被跳过读取。\n\n"
"三、考勤时间判断规则\n\n"
"默认班次:\n"
"上班时间为 08:00,下班时间为 17:00。\n"
"若员工打卡时间晚于 08:00,则记为迟到。\n"
"若员工下班打卡时间早于 17:00,记为缺卡。\n\n"
"学员服务中心_早班:\n"
"上班时间为 08:00,下班时间为 17:00。\n"
"判断早班情况:\n"
"若员工打卡时间晚于 08:00,或者在 08:00 但分钟数大于 0,则记为迟到。\n"
"若最后一次打卡时间不在 17:00 之后,则记为缺卡。\n\n"
"学员服务中心_晚班:\n"
"上班时间为 10:00,下班时间为 19:00。\n"
"若员工打卡时间在 10:00 之前或者 19:00 之后,则认为是晚班。\n\n"
"四、功能介绍\n"
"导入文件:\n"
"通过点击 “选择文件” 按钮,可以选择要导入的考勤数据 Excel 文件。\n"
"导入后,系统会自动读取文件内容,并在树形控件中展示考勤概要。\n\n"
"显示考勤概要:\n"
"树形控件展示的考勤概要包括工号、姓名、部门、迟到次数、缺卡次数、正常休息天数、额外休息天数和晚班次数。\n"
"可以点击 “部门” 列标题对员工进行排序,但导出统计数据时不会根据排序后的结果导出。\n\n"
"导出统计数据:\n"
"点击 “导出统计数据” 按钮,可以将统计后的考勤数据导出为一个新的 Excel 文件,文件名为 “考勤统计汇总.xlsx”。\n\n"
"五、注意事项\n\n"
"软件在运行过程中可能会出现错误,如无法加载文件等情况,请检查文件格式和内容是否正确。\n\n"
"在处理考勤数据时,系统会根据设定的规则进行统计,但可能会存在一些特殊情况无法准确判断,需要人工进行核实。\n\n"
"导出的统计数据仅为当前导入文件的统计结果,不会保留历史数据。若需要多次统计,每次都需要重新导入文件。\n\n"
"软件由“一颗大白菜”设计开发,如遇到问题可联系本人调整。微信、QQ:35515105 电话:18686626826 。\n\n"
)
# 创建文本框
text_box = tk.Text(info_window, wrap=tk.WORD)
text_box.insert(tk.END, info_text)
text_box.config(state=tk.DISABLED) # 设置为只读
text_box.pack(padx=10, pady=10, fill=tk.BOTH, expand=True)
# 创建 GUI
root = tk.Tk()
root.title("考勤管理系统")
root.geometry("800x600")
root.minsize(800, 600)
frame = tk.Frame(root)
frame.pack(padx=10, pady=10, fill=tk.BOTH, expand=True)
# 添加说明按钮
button_info = tk.Button(frame, text="说明", command=show_info)
button_info.grid(row=0, column=0, padx=5, pady=5)
button_browse = tk.Button(frame, text="选择文件", command=browse_file)
button_browse.grid(row=0, column=1, padx=5, pady=5)
button_export = tk.Button(frame, text="导出统计数据", command=export_marked_data)
button_export.grid(row=0, column=2, padx=5, pady=5)
# 添加进度条和标签
progress_var = tk.DoubleVar()
progress_bar = ttk.Progressbar(frame, orient=tk.HORIZONTAL, length=400, variable=progress_var, maximum=100)
progress_bar.grid(row=0, column=3, padx=5, pady=5)
progress_label = tk.Label(frame, text="进度")
progress_label.grid(row=0, column=4, padx=5, pady=5)
# 设置树形控件并定义列宽
tree = ttk.Treeview(frame, columns=("工号", "姓名", "部门", "迟到次数", "缺卡次数", "正常休息天数", "额外休息天数", "晚班次数"),
show="headings")
tree.heading("工号", text="工号")
tree.heading("姓名", text="姓名")
# 获取部门列的索引
department_index = tree['columns'].index('部门')
tree.heading("部门", text="部门", command=lambda: sort_treeview(tree, department_index))
tree.heading("迟到次数", text="迟到次数")
tree.heading("缺卡次数", text="缺卡次数")
tree.heading("正常休息天数", text="正常休息天数")
tree.heading("额外休息天数", text="额外休息天数")
tree.heading("晚班次数", text="晚班次数")
# 设置各列的宽度
tree.column("工号", width=10)
tree.column("姓名", width=50)
tree.column("部门", width=50)
tree.column("迟到次数", width=20)
tree.column("缺卡次数", width=20)
tree.column("正常休息天数", width=30)
tree.column("额外休息天数", width=30)
tree.column("晚班次数", width=30)
def show_missed_details(event):
item_id = tree.identify_row(event.y)
if item_id:
# 获取选中行的工号、姓名、部门
emp_id = tree.item(item_id, 'values')[0]
name = tree.item(item_id, 'values')[1]
department = tree.item(item_id, 'values')[2]
if filepath:
original_df = pd.read_excel(filepath, header=None, skiprows=4,
names=['工号', '姓名', '部门'] + [str(i) for i in range(1, 32)])
details_df = original_df[(original_df['工号'] == emp_id) & (original_df['姓名'] == name) & (original_df['部门'] == department)]
# 创建一个新的窗口展示明细表格
detail_window = tk.Toplevel(root)
detail_tree = ttk.Treeview(detail_window, columns=details_df.columns.tolist(), show="headings")
for col in details_df.columns:
detail_tree.heading(col, text=col)
# 设置列宽
for col in details_df.columns:
if col in ['工号', '迟到次数', '缺卡次数', '晚班次数']:
detail_tree.column(col, width=20)
elif col in ['姓名', '部门']:
detail_tree.column(col, width=50)
else:
detail_tree.column(col, width=30)
# 插入数据
for index, row in details_df.iterrows():
detail_tree.insert("", "end", values=tuple(row))
detail_tree.pack(padx=10, pady=10, fill=tk.BOTH, expand=True)
tree.bind("<Double-1>", show_missed_details)
tree.grid(row=1, column=0, columnspan=4, padx=5, pady=5, sticky='nsew')
scrollbar = ttk.Scrollbar(frame, orient=tk.VERTICAL, command=tree.yview)
scrollbar.grid(row=1, column=4, sticky='ns')
tree.configure(yscrollcommand=scrollbar.set)
frame.columnconfigure(0, weight=1)
frame.rowconfigure(1, weight=1)
def sort_treeview(tree, column_index):
"""对树形控件进行排序"""
items = [(tree.set(item, column_index), item) for item in tree.get_children('')]
sorted_items = sorted(items, key=lambda x: x[0])
for index, (_, item) in enumerate(sorted_items):
tree.move(item, '', index)
root.mainloop() |
| 你好优秀经办人微信公众号 |




![[优秀经办人]品牌](http://ccxb.net/c20062a4916fa3f59f5409ddfdddd15f.jpg)

